Shared Scientific Toolbox
The Shared Scientific Toolbox in Java
Introduction
The Shared Scientific Toolbox in Java (SST) is a collection of foundational scientific libraries. Its primary purpose is to serve as a bridge between the highly specific demands of involved scientific calculations and the more traditional aspects of the Java programming language. True to the Java way, the SST strives for idioms and primitives that are powerful and yet general enough to enable the user to write concise, correct, and fast code for most scientific tasks. The SST is best suited for deployment code where integration and portability are priorities -- in other words, prototype in MATLAB, deploy in the SST.
Features
The SST includes many member packages with the goal of simplifying scientific programming. These include and are not limited to:
- A full-featured multidimensional array package supporting slicing operations, elementwise operations, dimensionwise operations, FFTs, and linear algebraic functions.
- A highly scalable, asynchronous sockets API built on top of java.nio.
- A parallel dataflow engine that facilitates the exploitation of multicore hardware.
- Plotting abstractions that provide a consistent, easy way to leverage the power of plotting packages like Gnuplot.
- Declarative, annotation-driven APIs for resource loading, command-line parsing, and message passing.
- Numerous convenience classes that improve upon existing java.* foundation class functionality.
The next five sections offer a cross section of the features described above.
Multidimensional Arrays -- org.shared.array
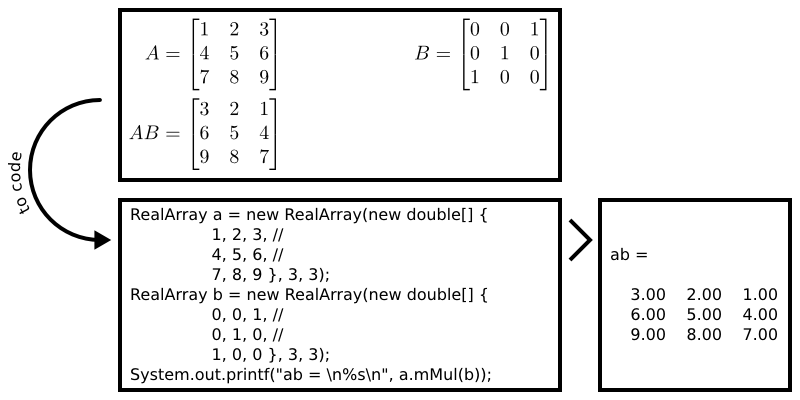
The org.shared.array package allows the user to interact with multidimensional numerical data in a structured, concise manner. The following picture demonstrates how one goes about multiplying two RealArrays (which happen to be two-dimensional and interpreted as matrices).
Users of this package may enjoy many potential benefits:
- A breadth of operations comparable to that of MATLAB.
- Multidimensional FFT operations backed by the award winning FFTW3 package.
- Execution of native code whenever shared libraries or DLLs are available through the JNI.
- An arbitrary number of array dimensions.
- A generic ObjectArray class that can hold anything.
- Your choice of row major or column major indexing and the ability to convert between the two.
- An experimental sparse array class that supports an arbitrary number of dimensions.
- Arrays permitting an arbitrary number of dimensions. Matrix operations are provided through an interface whose methods work on arrays that happen to be two-dimensional.
- Orthogonal design to increase extensibility, maintainability, and understandability.
High Performance Networking -- org.shared.net
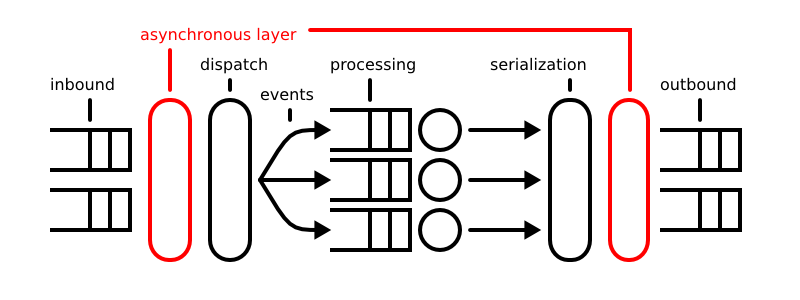
An asynchronous model for sockets, aside from the performance benefits associated with being built on top of select, can reduce programmer error through a concise API and well-defined set of usage conventions. The SST implements a complete messaging layer upon which high level protocols may be built. Users may override any level of the networking stack, with the choice dependent on the level of specific functionality desired. The end goal is to empower users to build scalable, thread-safe distributed programs. The illustration below demonstrates a fairly typical, network-aware message passing architecture in the style of SEDA, with the asynchronous sockets layer marked in red. In it, packets come in from asynchronous sockets; packets are transformed into events; events are then dispatched to processing units; processing units serialize response events; and finally serialized responses are written back to asynchronous sockets.
The subsystem described above offers significant advantages over the traditional one-thread-per-socket model of network programming:
- Consistent performance under thousands of concurrent connections. The internally multithreaded design applies otherwise idle CPU resources toward non-blocking socket I/O.
- Callback reads and asynchronous writes, which remove programmer responsibility for ensuring that mission critical code does not block.
- A realization of the intercepting filter pattern that separates protocol and endpoint logic concerns. As a consequence, pluggable SSL/TLS transport and XML DOM parsing are available to the programmer with ε additional effort.
- Compact, orthogonal, type-safe design both in terms of lines of code and economy of API concepts. Internals are hidden from the user in an effort to prevent misuse and bugs.
Switching from traditional I/O constructs to an NIO framework requires careful initial consideration; consequently, we invite you to peruse the networking chapter of the user manual to see if the SST's networking layer is appropriate for your problem. If not, do check out the excellent Apache MINA and Netty projects as alternatives.
Parallel Dataflow Engines -- org.shared.parallel
A parallel dataflow engine separates the specification of a parallel computation from the actual execution of it. All that is required from the user is a description of the atomic units of work involved and their interdependencies. Upon receiving an input, the engine will carry out the computation in parallel to the fullest extent that its dependencies allow. The illustration below depicts a very simple engine whose nodes perform arithmetic operations on their inputs. Conceptually, one may view engine execution as pushing, and in the process transforming, an initial input from a source node through a series of calculation nodes to an eventual sink node.

The above approach has multiple computational and organizational advantages:
- Elimination of potential bottlenecks by encouraging users to break computations down into small tasks and scheduling tasks as soon as dependencies are met.
- A methodical way to deal with repetitive, parameterized computations. Feature extraction routines for machine learning would benefit greatly from decreased code complexity and increased throughput resulting from parallelism.
- Removal of task scheduling on multicore hardware from the programmer's list of responsibilities. Although prototype systems like JCilk have this benefit, they require Java language extensions and do not run on vanilla JVMs.
Statistical Tools -- org.shared.stat
Whereas MATLAB is a sheltered execution environment with all statistical tools in one place, the SST, being compatible with vanilla Java code, takes a mix-and-match approach.
In providing a statistical package, we pay particular attention to design and abstraction, since these are what the base language encourages.
Time constraints, however, dictate the implementation of only a handful of concepts -- we welcome the user to check out what's currently available (e.g., classes for combinatorics and Gaussian mixture modeling).
One noteworthy subpackage is org.shared.stat.plot.
Here, one will find abstractions modeled for basic plotting functionality.
Currently, we provide a Gnuplot-backed implementation of the interfaces.
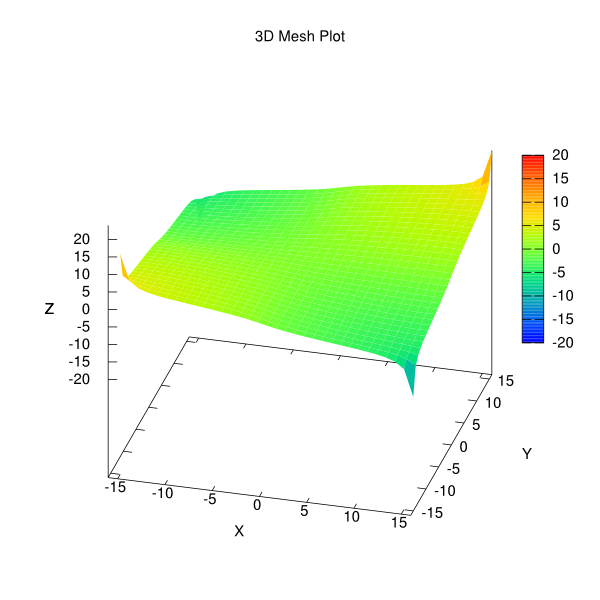
Consequently, we were able to generate the surface plot shown below with 14 lines of non-Gnuplot-specific code.
Annotation-Driven Class Loading -- org.shared.metaclass.Loader
In addition to calculation-driven libraries, the SST contains declarative, annotation-driven APIs that attempt to reduce the tedium of writing repetitive, boilerplate code. With Java 1.5 annotations, programmers can describe how their program is supposed to work without having to write control flow logic.
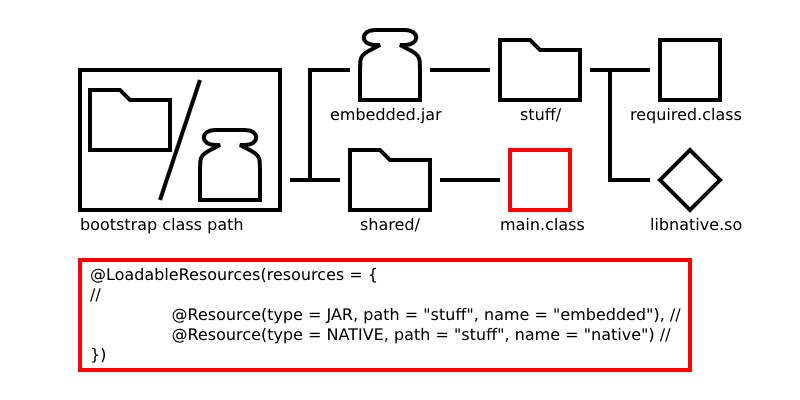
One such annotation-driven API marshalls resources and loads them on program start. Normally, programs depend on third party libraries, and, by association, their Jar files. In general, it's not good practice to unpack Jar files and dump their contents onto the main class path. Declaring an overly long class path for the system class loader isn't a viable solution either, as one exposes the underlying needs of the program to a shell script or the like, and that breaks portability. The SST program loader addresses the above issues by inserting a level of indirection between resource management and program execution. The illustration below demonstrates just how the loader interrogates a designated main class for resource targets (delimited in red along with annotations). Quite simply, the annotations say that the paths found in "embedded.jar", which itself is a resource on the bootstrap class path, should be visible to a newly created RegistryClassLoader. Moreover, as an added service, said class loader should also load the native JNI library "stuff/libnative.so".
By controlling class loading behavior with annotations, users can achieve the following effects:
- Jar-in-Jar deployments equivalent to those possible with classworlds.
- Packaging and loading native libraries as part of Jar-in-Jar distributions and declaring their presence with annotations.
- Fine-grained control over class loader delegation rules that may diverge from Java's default model.
Downloads and Documentation
To send you on your way, here's how to obtain the SST and/or learn more about it:
- Downloads of source and Jar distributions.
- A user manual of usage examples and design philosophy.
- Javadocs of member classes, or, for the eternally curious, Doxygen of the native components.
- A Git repository of browseable code.
The fastest way to test drive the SST is to download the pure Java distribution, given as a Jar, and type
java -jar sst.jar,
which will kick off a suite of JUnit tests.
No functionality is lost in using pure Java backend bindings; however, we highly recommend compiling the native layer for speed.
Thus, once you are satisfied that the SST will meet your needs, download the full, Tar'd distribution and build the Java sources as well as the C++ sources constituting the native layer.
Windows users may benefit from a special source distribution that contains precompiled DLLs and a special executable, buildandtest.exe, for compiling Java classes and unit testing the whole package.
Finally, Eclipse users can import the source distribution or version control working image, which contain .project and .classpath files, directly.
Note that the IvyDE plugin is required to properly set up the class path.
Make sure you have Java 1.6.*+ handy. Contact the administrator if you have any lingering doubts and/or questions.